Unlocking the Potential of Data Science,
Machine Learning, and Artificial Intelligence
Aligning data, domain expertise, and infrastructure to turn AI initiatives into measurable enterprise value.
Executive Summary
This whitepaper outlines how a structured Enterprise AI Strategy enables organizations to move beyond experimentation and deliver measurable business impact. It explores the role of organizational alignment, data readiness, domain expertise, and scalable infrastructure in building reliable, production-ready AI systems.
00
Introduction
From early AI research to today’s enterprise-scale applications, artificial intelligence has become a core driver of business innovation. However, success depends not just on models or tools, but on a clear Enterprise AI Strategy that aligns technology with business priorities, data foundations, and cross-functional collaboration.
Many AI initiatives struggle to move beyond pilots because ownership, decision-making structures, and infrastructure are not designed to support them. What appears to be a technical limitation is often a strategic or operational gap. When guided by defined goals, strong data practices, and domain expertise, AI can improve operations, customer engagement, talent management, and financial performance.
In this paper, we outline the organizational roles, data considerations, and infrastructure elements required to build an effective Enterprise AI Strategy that turns experimentation into sustained business value.
The Business Value of an Enterprise AI Strategy
Let’s review the areas of your enterprise in which AI-ML applications can be beneficial. AI-ML generally help with identifying subtle patterns in large data. Additionally, if there are repetitive tasks, it is likely that they can be automated with the help of AI and/or robotics; but of course, there will always be tasks that are hard to automate even with AI. When using AI-ML applications, we believe four main areas within a typical business would likely benefit the most: Operations, Customer Engagement, Talent Management, and Financial Management/Risk Management.
For operations, data can identify areas of inefficiency and offer solutions. For example, if your business sells goods, AI can help you track your inventory, forecast demand, and adjust the orders. More and more, customers expect a smooth and pain-free experience for every transaction. Part of that experience is your store ideally having every item in stock.
Additionally, recommendation systems (such as those used by Amazon) can help in keeping customers coming back. AI also has the potential to transform onboarding and talent retention. AI can cater to an individualized onboarding experience and offer incentives to retain your talent. In the finance department, AI can help identify fraudulent transactions or quickly identify transaction errors. The latter has the additional benefit of increasing customer experience. There are situations in which analytics, not necessarily AI, would help your business make informed decisions. One of the simplest examples is experimentation involving A/B Testing to determine which version of your product would be most likely to succeed upon release. These analytics can be uncovered using visualizations and/or statistical models.
The application of data science, ML, and AI is vast. Listing details about these applications is outside the scope of this article. However, we can offer some numbers that may motivate your company to incorporate a data science practice.
According to the McKinsey Global Survey, 79% of 1,843 participants attributed AI as part of their business cost reduction in 2020 [1].
Across the globe, AI adoption in at least one portion of the business has increased to 57% compared to 50% in the previous year. Out of those companies with AI application(s) with successful cost reduction, 30% of them saw more than 20% expense reduction. As a side note, the 2019 to 2022 AI adoption increase is sharper in emerging economies such as China. We also believe that analytics and data reporting will likely uncover insights for the inefficiencies in your processes. Investing in the data infrastructure and data analysts would bring in a faster return on your investment. In fact, they build a nice stage for ML and AI practice by providing a platform and domain expertise. If your company does not have talent in data infrastructure and analytics, the data science team might be unreasonably burdened.
We have been helping small to medium sized enterprises as well as large enterprises in their digital transformation journey for about 20 years. We have worked with over 400 companies from various domains, such as multimedia, finance, and healthcare. In our journey, we have learned practices that result in revenue, and we have also seen practices that do not see the light beyond exploratory work. Very few companies today have been able to reap the real benefits of data and AI. If you are now convinced that you want your business to make data-backed informed decisions or incorporate AI as part of the practice, in this paper, we will be providing some guidelines as to what to keep in mind when starting your practice. We hope that these guidelines will help in the successful incorporation of ML & AI practice resulting in organizational efficiency and business/revenue growth.
In this paper, we discuss the roles of three organizational entities that play key roles in data science practice:
(1) data science, data engineering and machine learning team
(2)domain experts and analysts who have knowledge of the business and day to day activities.
(3) business unit comprises of stakeholders who oversee roadmaps, prioritize the projects, allocate the resources, and take care of process bottlenecks. We stress the roles of domain experts and stakeholders in a productive data science practice.
These entities are involved in overseeing five critical elements of the practice:
- Collaboration between data science and business stakeholders
- Setting achievable goals with measurable impact
- Domain knowledge
- Data availability and quality
- Infrastructure
These outcomes are most sustainable when guided by a structured Enterprise AI Strategy rather than isolated AI experiments.
In the following sections, we discuss these points and our industry experience. We conclude this paper with our outlook moving forward.
Collaboration in an Enterprise AI Strategy
Business units and data science teams in small and medium-sized enterprises often work in silos. The business decision-makers do not know the data science capabilities and what kind of projects can be executed to help the business. On the other hand, data science teams may not be fully aware of the business problems and their impact. If your business does not already have a fluid communication between the two units, bridging this gap is a foundational requirement of any successful Enterprise AI Strategy.
We have found that knowledge transfer between the teams results in a better outcome. Involving all teams in the discussions can create a constructive environment in which its product is magnificent. We understand that making these communications may be difficult. However, a willingness and patience to learn from each other are critical to the success of a data science project.
Our Venture with Glucometer Chatbot
In our interactions with various clients, we come across a wide range of communication and interaction levels. Many companies have a clear demarcation of business and technical units. Some companies have better communication between these two units. We had an experience with a client whose level of communication and involvement left us impressed and with a more than successful outcome.
A Bluetooth-enabled glucometer manufacturer in India approached us to add diabetes advice functionality to their chatbot. The chatbot was there to help customers select a product. To us, this requirement seemed odd at first, so we talked to their project managers. They explained that some patients who bought the glucometers do not understand the meaning of the glucometer readings and seek advice on what to do, given their results.
Our client wanted to help these patients in order to build a brand with diabetes expertise. When they provided us with about 50 previously recorded conversations between medical representatives and patients, we told them that we would need more conversations to properly train their chatbot.
The product managers then started asking questions about how chatbots are trained. The company had access to doctors, dietitians, and health experts, so they suggested that we work more closely with them. Together with these experts, we developed a simulated dataset that covered common diabetic problems in addition to identifying medically critical cases from each generated scenario. We were amazed by their cooperation level and the understanding they gained during the project.
On the other hand, our team learned medical details about diabetes, e.g. type 1 and type 2. The project was successful due to their vision and collaboration, which resulted in a spinoff company that helps diabetic patients manage their health.
Setting Achievable Goals with Measurable Impact [Business-Centric vs Data-Centric Approach]
AI and ML have led to remarkable achievements in the last decade. However, it has been a subject of intense media hype and their capabilities frequently appear in mass media articles, speaking of a future with intelligent chatbots, self-driving cars, and virtual assistants. In general, these articles do not address how AI would be used in an organization for typical challenges like operations, customer engagement, talent management, and risk management discussed above. Hiring a team of data scientists/statisticians and involving them in exploratory data has been a prevalent route to start data science practice. However, we have seen that involving business stakeholders and domain experts in setting up goals with business impact results in successful projects; exploratory analysis of available data often dies out. Defining measurable outcomes ensures the Enterprise AI Strategy remains aligned with business priorities.
3.1 Business Centric Approach
In a business-centric approach, we start with stakeholders and domain experts to identify problems with high business impact without worrying about the data and algorithms. Together with client’s domain experts and data scientists, we can identify the data, associated challenges, and line of attack to achieve the goals. The projects with a business-centric approach get proper priority, funding, resources, visibility, and project structure. Their measurable impact and attention result in higher chances of success. Even if they fail, they fail fast, freeing up resources for other impactful projects, as desired in an industrial setting.
To give you an example, we worked with a client on various marketing strategies for obtaining leads and journey from prospects to paying customers. Although solutions like Salesforce Einstein provide similar analytics, they aimed to take control of the process and apply advanced methods. Prospect pipeline prioritization is not a well-published topic in literature and the web. This problem was nonintuitive and difficult to solve, however it had a significant business impact. Eventually, working together with marketing experts and data scientists we found solutions in a mix of customer churning, survival analysis, and probabilistic modeling. They gathered relevant data and successfully applied probabilistic models to rank prospects by likelihood of becoming paying customers.
3.2 Data Centric Approach
In a data-centric approach, we showcase data science capabilities by making the best use of the available data. The projects of this scheme are usually exploratory, largely leveraging published art, work of open-source communities and academic institutions. Often this exploration becomes indefinite due to new research in AI, new data, or a change of approach by data scientists. Even if projects are successful, they have lower chances of going to the next stage due to misalignment with company priorities. This approach is prevalent today, and we find it partly responsible for the negative impression of data science not contributing to the revenue.
We come across organizations that follow this approach, especially with new data science teams having little business knowledge. Data creation and warehousing make it appealing to explore the data following this approach. For example, the manufacturing industry records a lot of sensor data. Web analytics provides large amounts of data that might look appealing to start data-centric projects. We usually work with the business to narrow the scope of the project and encourage these teams to find business impact first.
3.3 Setting achievable goals
When working on scoping projects with clients (again, the emphasis here is communication), we work on setting goals and metrics regardless of the approach we are taking. Sometimes clients approach us with over-ambitious goals, which might look like a good challenge for ML. However, upon closer inspection, the project requires more data and development time than what the client is willing to spend.
For example, we were working with a media company that wanted an audio processing program for identifying profanity in movies.
- They asked us to develop a speech-to-text system that can correctly convert any audio to text.
- We agreed that we could develop such a program; spelling correctly is a challenging task that is not necessary for this application.
- We also added that speech-to-text solutions exist already, but they are not universal and mainly work in conversation settings.
- Because of the broad nature of the application, using this as an underlying model would likely become computationally costly.
- We advised that a spoken language understanding solution has shown improved precision and lower false alarms for a limited vocabulary such as profanity, for example, the work of Lugosch et al at Facebook [2].
00
The Role of Domain Expertise in an Enterprise AI Strategy
Data Science, ML, and AI applications do not exist without domain experts. Domain experts shape evaluation metrics, making them essential contributors to an effective Enterprise AI Strategy. They infuse their domain and business knowledge in ML models by:
(a) setting the model evaluation metrics
(b) assigning weights to various errors and
(c) curating test data and overseeing the evaluation scheme.
Any model produces errors, whether it be because of biased data, wrong assumptions, etc. Domain experts’ perspective (and diverse perspective) makes data science useful and relevant to the businesses. These errors have different impacts on processes and the final product. The ingrained knowledge from domain experts, as well as the diverse perspective, can make an impact on how successful the result is. These partnerships help us identify these errors, assign their relative weights, and develop business-oriented evaluation metrics. After these error weights are identified, we either incorporate the error correction into the ML model or develop a post-processing correction routine. We further emphasize the importance of domain expertise in testing and evaluations in the coming sections.
In a classification setting, there are two types of errors that a model can make: false positive and false negative [3]. False positive is like calling a good product defective, whereas false negative is giving QC approval to a defective product. Without domain knowledge and business rules, data scientists tend to assign equal weights to both types of errors. Setting these weights without domain insights can be harmful to the business.
For example, we were helping a client develop a product inspection model for solar cells. The developed solution would reject only when the model was absolutely sure of defects and would pass in case of doubt. We developed these rules of error weights by manufacturing engineers’ guidance to bring balance to discard defective products while keeping the scrap rate low. In some scenarios, domain experts might suggest more conservative error weights; for example, the model should not approve a loan for a marginal credit score. Working with domain experts to develop error weights and model evaluation metrics is the key to the solution with built-in business insights [4].
Data Readiness for an Enterprise AI Strategy
A lot of data is being produced every second now. However, often, there is a scarcity of useful data that is ready for data science work. Most enterprises these days have systems that generate the data and store that data. A common argument for storing all collected data is that it may become useful someday. In these situations, companies are afraid of throwing away data and end up spending a fortune on storage. We do admit that it is impossible to foresee and know the best data to store. However, we have enough experience to understand common data usage and the best data architecture practices to save cost. Ultimately, your business is in control of what you would want to keep. We collaborate with your organization to come up with the best-catered solution.
In most data science, ML, or AI applications, we cannot use the collected raw data. Therefore, despite the over-abundance of data, this raw data would have to be transformed to become useful. The relevant data is often unstructured and unlabeled, which is not what is needed for data modeling. These transformations can be painstakingly time-consuming and labor-intensive. Once the data is properly transformed and curated, useful data may become scarce. There are multiple ways to deal with this lack of data. We will introduce two common techniques, transfer learning and augmentation, specific to ML, that help alleviate the data scarcity.
5.1 Transfer Learning
Transfer learning is a commonly used technique in deep learning which needs specially transformed data called embeddings [3]. A large amount of data is needed to generate efficient embeddings. Often, companies don’t have enough data to make good embeddings. However, a third-party data or model related to the use case at hand can be used to generate the embeddings. For example, in an AI solution that can differentiate between weeds and crops to selectively apply pesticides, large data containing vegetation can be used to generate embeddings. The use of these embeddings significantly reduces curated data requirements.
5.2 Data Augmentation with Enterprise AI Strategy
Another commonly used technique to compensate for the lack of data is data augmentation [5]. Data augmentation pertains to creating new instances of data from existing ones. For example, if we have an image of a dog and flip it left to right, it is still an image of a dog. A machine learning model, however, sees this as a new data point instead of the same picture rotated. Other examples of image augmentations include the addition of noise, lighting, or a change in focus. Audio augmentation involves changing the frequency, loudness, pitch, and spec augmentation [6]. Previously, we have worked on developing new augmentation methods to cater to a specific need.
For example, we previously worked on developing an audio model to detect gunshots in movies for a media company.
- We found that Google’s Yamnet model can differentiate over 500 types of sounds, including gunshots [7].
- Because of how the Yammet model is designed, if a gunshot sound is split between two consecutive frames of 500 ms, the model may fail to detect it.
- We wanted to make a customization so that no gunshots are missed.
- Fortunately for us, Google released the data used to train the Yamnet model [8].
- However, we are cautious when using third-party data because we were not involved in the generation of these embeddings (including labeling).
- We do not know what kind of biases the data have and what kind of effect these biases would have on the model.
- Our goal is to detect gunshots in movies, but that was not the main goal of the Yamnet model.
- In order to further understand the underlying data, we listened to several movies and TV shows from the customer database and compared them with the Google dataset.
- We noticed several differences:
> The YouTube videos involved people with real gunshots in open spaces, whereas movie gunshots resemble audio in closed spaces like hotel rooms, banks, etc.
> Most YouTube clips were recorded using a cell phone whose capabilities do not record the full spectrum of audio frequencies used in movies.
> Many YouTube files contain videogame recordings that are clearly different from those in movies.
> Most movie scenes contain some background music that is not present in YouTube clips.
- From these learnings, we carefully curated an audio dataset by removing irrelevant audio clips.
- Further, we produced augmented audio data by mixing YouTube clips with movie clips with a range of audio energies.
- For testing the models, we only used our client’s data by painstakingly annotating every gunshot from a few movies in each genre.
5.3 No data out of thin air
Sometimes, there is really no way to compensate for the lack of data. Therefore, we recommend being intentional about the type of data you collect. The format in which data is stored is also important. For example, we sometimes encounter data stored in an aggregate form instead of the original raw data. Aggregation is a perfect format for databases, but in data lakes, generally, raw data is stored; this aggregation format may lose value when we want to do some analysis. We have run into a similar problem as this before. Our client kept information on their products’ descriptions (e.g., their product price, items in stock, warehouse location, etc.)
Some of this information was also client-facing, so they took extreme due diligence to keep the database up to date and accurate. However, every time a change was made to the product information, the database was overwritten. When they wanted to look at historical data, they were not set up to do so. Fortunately, our client kept a log of when any change was made to entries in the database. We were able to use that log along with the current database to recreate historical data and started a process to set up a separate database for data science work without affecting the production database.
5.4 Test dataset and testbench: Having robust test data for your models
In general, three different datasets are used for developing an ML solution: training data, validation data, and test data [9]. Validation data is used to tune the models. Although a model is not trained on the validation data, during the iterative process of tuning, information from this validation set is indirectly leaked into the model.
The test data should be kept separate and used only to determine the performance of the model. It should be used only a few times for this testing purpose only. Some organizations test their models very rigorously. They involve domain experts and business leaders to create and curate the test data and keep it away from the data science team.
The transfer learning and augmentation methods are not used for test data. If the model is not satisfactory, the detailed test results are not shared with the data science team. Irrespective of whether model development is done in-house or outsourced, every organization should have well-curated test data and a way to evaluate the models. This cannot be done without the involvement of domain experts and business leaders. We have seen models that do not get deployed because business and domain experts are not convinced by the results and data provided by the ML team.
Infrastructure Foundations for an Enterprise AI Strategy
Scalable infrastructure ensures the Enterprise AI Strategy can move from pilots to production reliably. If you are reading this, data is most likely central to your organization. Handling large amounts of data is a full-fledged discipline. There is a large amount of literature on various aspects of data, for example, the 6-Vs of data: volume, variety, velocity, value, veracity, and variability. The cloud infrastructure is designed to attend to all these aspects of data. However, a lot of companies have data on-premises. Startups and new companies generally start with the cloud, and more companies are migrating their data from on-premises to the cloud. In addition to data management, data security and legal compliance are important considerations. Data Lakes and ML Ops are needed to enable data scientists to develop advanced solutions.
6.1 Data Lakes
- Two popular data management schemes are data warehouses and data lakes. Data warehouse follows the extract, transform and load (ETL) structure, whereas data lakes follow the extracted load and transform (ELT) structure.
- In a data warehouse, we know how data would be used, so we transform it before saving it. On the other hand, data lakes contain a variety of data that needs to be transformed based on the need.
- With data storage solutions becoming more affordable, many companies started to adopt having a data lake and ELT structure. With the ELT format, the process of transforming data and storing it in a database generates the necessity of a new role that is not quite a Data Engineer and not quite a Data Analyst.
- These days, we hear the term Analytics Engineer to describe this role. By the way, this naming convention is by no means consistent across the industry. Their main task is to generate pipelines that would transform the data to maintain an easy-to-access data warehouse.
- Having the pipelines automated saves time for analysts who are often working on making dashboards for data reporting. Having one central data warehouse has the added benefit of making data reporting consistent across your enterprise and minimizing confusion.
- Data scientists can also benefit from having these formats in the same way that analysts do. They can have a consistent data source and concentrate on making statistical models or ML models. There is always going to be a need for custom transformations, but by having centralized transformation pipelines, this need may be reduced. We describe a generic architecture of the data lake in Appendix B.
6.2 ML Ops with Enterprise AI Strategy
In addition to the data pipelines described above, a separate infrastructure involving ML Ops to support model development, tracking, update, and deployment is required. Similar to the versioning of code, data changes over time, and those changes should be tracked along with the models. As new data comes in, we would like to update models with the new data. On the other hand, we might have well-curated data or well-established features. Hence, we might want to trigger model training when we make changes in the model architecture. The model training, update facilities along with, model evaluation, and model comparison should be automated. In addition to setup data management, we also build ML Ops infrastructure for our clients so that their data scientists focus on core business and model development while automating most of the repetitive work. We show a generic architecture of ML Ops using ML Flow in Appendix B.
Conclusion
Our hope is that we have provided some information for starting your enterprise data journey so that your data science/ML team becomes successful and brings value to your company. We hope that we also provided the importance of having a robust data infrastructure to support your data science team. If your company is already amid building your data science, ML, or AI project, we hope that your company is empowered to have the infrastructure necessary to support your team. Organizations that align people, processes, and platforms through a clear Enterprise AI Strategy are best positioned to realize sustained AI value. Success is in your hands, and we hope that we can be a part of that success if you seek additional support for your enterprise.
00
Appendix A
Data Lakes
This data engineering part of solution has been designed for customers with consideration of simultaneous data access by data science and business intelligence (BI) team.
The data comes from multiple sources:
(a) Data ingestion from Redshift
(b) Data ingestion from S3
(c) Data ingestion from streaming sources.
As shown in below figure, various Amazon services have been used. Amazon redshift – a fully managed, petabyte-scale data warehouse service in the cloud. Amazon S3 – an object storage service that stores data as objects within buckets. Amazon Kinesis Data Streams – a serverless streaming data service that makes it easy to capture, process, and store data streams at any scale. Amazon Kinesis Data Firehose is an extract, transform, and load (ETL) service that reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services. Lambda is a compute service that lets you build applications that respond quickly to new information and events. Amazon SageMaker – a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly, and Amazon Kinesis, which helps with real-time data ingestion at scale.
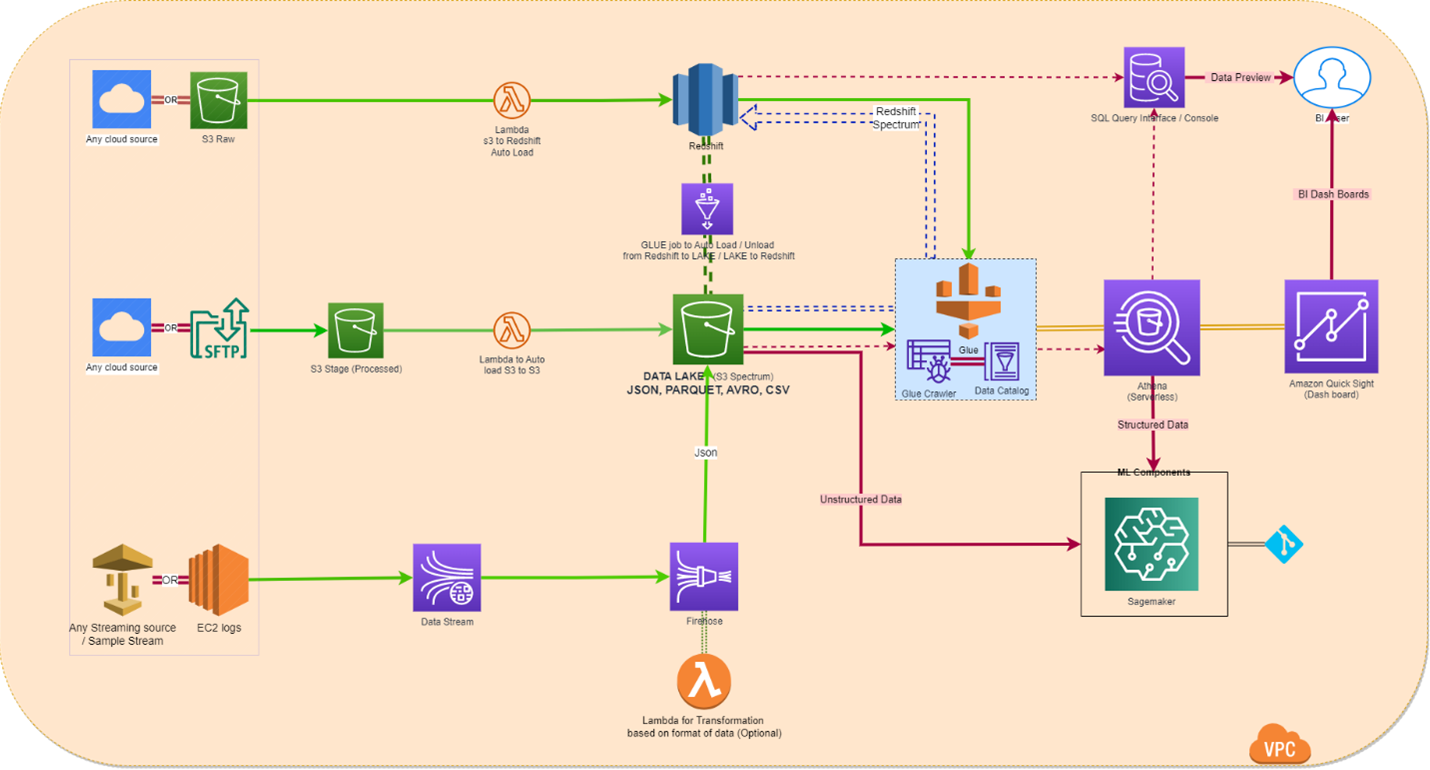
The diagram depicts the solution architecture, enables real-time data ingestion from either an External or any cloud platforms, and real-time data storage on a data lake. This functionality is specifically tailored for situations where there is a need for storing and organizing large amounts of real-time data on a data lake and direct access from lake without being loaded.
In this module, data is ingested from either any cloud or external source. The workflow is as follows:
- Data source for the redshift will be assumed as any cloud data sources, the processed or transformed data from redshift cluster can be directly accessible using SQL supported tools.
- Data source for s3 also will be assumed as any cloud or external based, here the data incoming treated as structed or unstructured, the structed data can optionally loaded into an Amazon Redshift cluster or it can be directly accessible without being loaded to Redshift cluster, this can be done by Redshift Spectrum, which is a feature of Amazon Redshift that allows you to query data stored on Amazon S3 directly and supports nested data types.
- The streaming data will be coming from an external source to kinesis data stream, which is a massively scalable and durable real-time data streaming service. Then this data feed the Firehose with help of lambda, streaming data reads by lambda, and it will perform the tasks like encryption, compression based on architecture needs.
- Streaming data is then automatically consumed by Amazon Kinesis Data Firehose. Kinesis Data Firehose loads streaming data into data lakes, data stores, and analytics services. It is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. Data captured by this service can be transformed and stored into an S3 bucket as an intermediate process.
- The stream of data in the S3 bucket can optionally loaded into an Amazon Redshift cluster using s3 copy and stored in a database or the stream of data in S3 bucket can be directly accessible through Redshift spectrum without being loaded to Redshift cluster.
- Data from all 3 channels can be directly accessible through redshift / redshift spectrum by BI users, Same cab be unloaded to S3 lake from redshift cluster and Intermediate buckets, the lake will be the final consuming point of data for ML models.
Appendix B
ML Ops
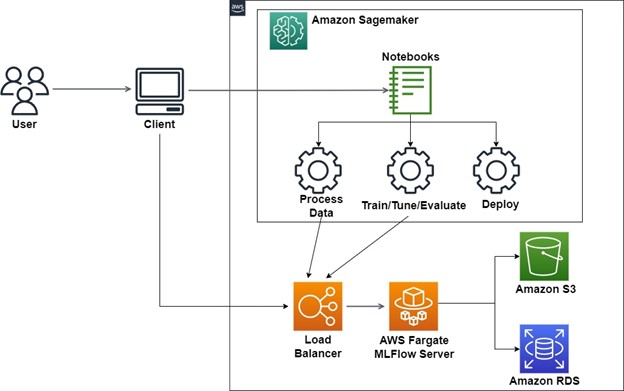
In earlier section, we discussed different architectures for ingestion of data from cloud or external data source to data lake S3 bucket and creating a data pipeline. This data lake becomes the final consuming point of data for ML models. During different phases of an ML project, data scientists need to track multiple experiments, manage different model versions going to production and their lifecycle to find solution to the business need. The open-source platform MLFlow helps manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. It includes the following components:
- Tracking – Record and query experiments: code, data, configuration, and results
- Projects – Package data science code in a format to reproduce runs on any platform
- Models – Deploy ML models in diverse serving environments
- Registry – Store, annotate, discover, and manage models in a central repository
MLFlow can be deployed on AWS Fargate and used in the ML project along with Amazon SageMaker. SageMaker is used to develop, train, tune, and deploy an ML model quickly, removing the heavy lifting from each step of the ML process.
In suggested architecture described in Figure 2, a central remote MLFlow tracking server is used to manage experiments and models collaboratively. This MLFlow server is dockerized and hosted on AWS Fargate. Amazon S3 and Amazon RDS for MySQL are set as artifact and backend stores, respectively. The artifact store is suitable for large data (such as an S3 bucket or shared NFS file system) and is where data science team log their artifact output (for example, models). The backend store is where MLflow Tracking Server stores experiments and runs metadata, as well as parameters, metrics, and tags for runs.
We can use databases such as MySQL, SQLite, and PostgreSQL as a backend store with MLflow. For this example, we set up an RDS for MySQL instance. Amazon Aurora is another MySQL and PostgreSQL-compatible relational database which can also be used for this. Post launching the MLflow server on Fargate, now the remote MLflow tracking server is running and is accessible through a REST API via the load balancer URI. MLFlow Tracking API can be used to log parameters, metrics, and models when running the ML project with SageMaker.
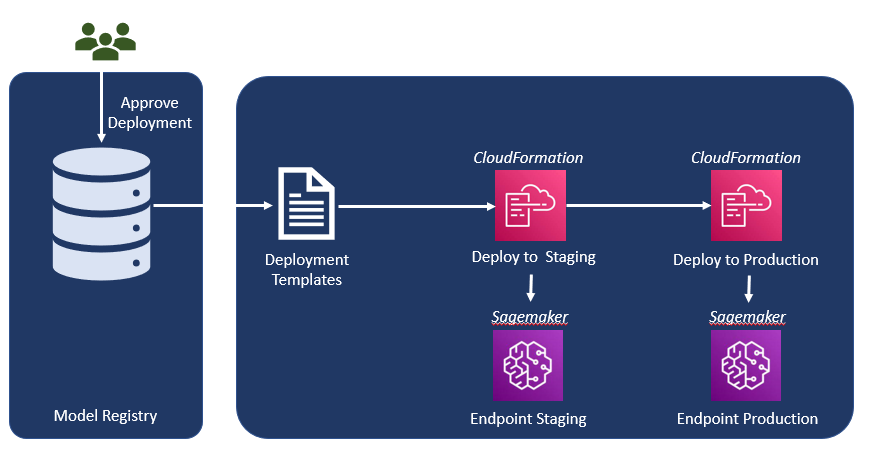
Models trained in SageMaker are registered in the MLflow Model Registry as shown in Figure 3. As a result, the pipeline will register a new model version in MLflow at each execution. Finally, the MLflow model is deployed into a SageMaker endpoint. Here SageMaker MLOps project and the MLflow model registry were combinedly used to automate an end-to-end ML lifecycle.
00
Is your AI strategy truly driving business impact?
Turn AI initiatives into measurable operational and revenue gains.
Author’s Profile
