Executive Summary
AI and machine learning are only as good as the data they’re trained on. Yet data annotation—the essential step of labeling training data—remains a costly, time-consuming, and error-prone bottleneck for many organizations.
Table of Contents
Manual labeling methods no longer scale. They falter under growing data volumes, modality complexity (text, image, audio, video), and rising quality demands from today’s AI applications.
Human-in-the-Loop (HITL) annotation solves this by combining automation with human oversight to create faster, more accurate pipelines. The HITL model enables machine-generated labels to be reviewed, corrected, or enhanced by humans—boosting model performance, reducing rework, and accelerating iteration.
This whitepaper provides a strategic, technical, and operational roadmap for implementing HITL pipelines.
It covers:
- Key challenges in manual annotation
- Design principles for scalable HITL workflows
- Strategic techniques like active learning, weak supervision, and RLHF
- Platform, team, and governance considerations
- Case studies showcasing real-world results
- How V2Solutions partners with enterprises to implement high-performance annotation systems
Introduction: The Data Labeling Dilemma
The Data Imperative
High-quality labeled data is foundational to every machine learning model. Whether it’s bounding boxes for computer vision, intent detection in NLP, or sentiment in speech, labeled data is what enables models to learn patterns and make accurate predictions.
Inaccurate, biased, or inconsistent labels directly impact downstream model behavior—resulting in failed predictions, hallucinated outputs, or unsafe model decisions.
The Bottleneck of Manual Annotation
Manual annotation has long been the default, but it doesn’t scale:
- It’s labor-intensive, requiring thousands of person-hours.
- It’s expensive, especially for complex, multi-class tasks.
- It’s inconsistent, with high inter-annotator variability.
- It’s slow, delaying model iterations and go-to-market timelines.
The Human-in-the-Loop Promise
HITL solves these problems by inserting human feedback into machine-assisted pipelines. It improves:
- Speed: Models auto-label low-risk data; humans focus only on complex cases.
- Accuracy: Human corrections are looped back to improve model performance.
- Efficiency: Reduces redundant manual work by using automation where it works best.
The Hidden Cost and Complexity of Annotation at Scale
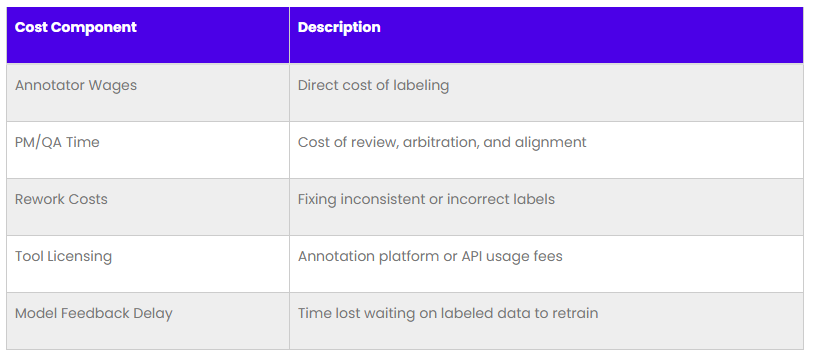
Annotation Costs Aren’t Just About Labor
True annotation costs include:
- Labor: Wages for annotators and leads
- Project Management: Coordination, reviews, revisions
- Rework: Correcting errors from poor initial labeling
- Tools: Licensing, integrations, custom tooling
- Slow Feedback Loops: Delays in model updates due to slow data turnaround
As your dataset and model complexity grow, so do these costs—often exponentially.
Breakdown of Annotation Cost Driver
Ensuring Annotation Quality and Consistency
Poor annotation quality breaks everything downstream:
- Model accuracy plummets.
- Retraining cycles get longer.
- Stakeholder confidence drops.
Annotation Quality Killers:
- Ambiguous task instructions
- Untrained or overworked annotators
- Lack of gold standard benchmarks
- No second-layer review or arbitration
Best Practices for Quality:
- Consensus mechanisms: Aggregate multiple labels to reduce bias
- Gold standard sets: Benchmark annotators and retrain them as needed
- Arbitration: Resolve conflicts with expert reviewers
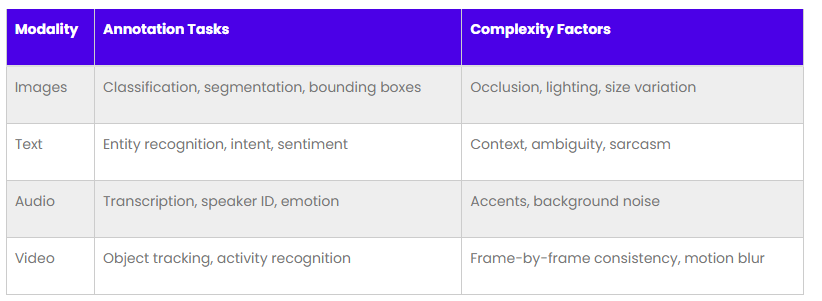
Managing Diverse Data Types and Modalities- Different Data, Different Challenges
Handling various data types requires specialized tools and expertise. For instance:
- Computer Vision (CV): Involves tasks like image classification, object detection, and semantic segmentation.
- Natural Language Processing (NLP): Encompasses text classification, named entity recognition (NER), and sentiment analysis.
Data Modality vs Annotation Complexity
Architecting Human-in-the-Loop (HITL) Pipelines That Actually Work
What Makes a Pipeline “HITL”?
A HITL system doesn’t replace humans or automate everything—it intelligently divides the workload:
- Machines label low-risk data
- Humans correct, validate, or guide complex cases
- The feedback improves the model, reducing future human workload
Core Principles of Effective HITL Design
- Active Learning: Prioritizing data samples that provide the most learning value.
- Weak Supervision: Utilizing heuristics and external knowledge to generate labels.
- Reinforcement Learning with Human Feedback (RLHF): Incorporating human preferences to fine-tune model behavior.
- Continuous Learning: Iteratively improving models with ongoing human input.
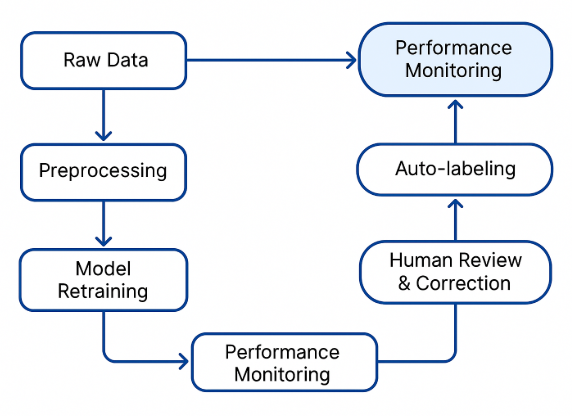
HITL Architecture: Core Components
- Data Ingestion and Pre-processing: Collecting and preparing data for annotation.
- Initial Model Prediction/Auto-labeling: Generating preliminary labels using existing models.
- Human Review and Correction: Annotators validate and correct machine-generated labels.
- Model Retraining and Evaluation: Updating models based on corrected annotations.
- Quality Assurance and Monitoring: Ensuring data integrity and tracking performance metrics.
Adaptive Improvement Over Time
Each loop improves model confidence, reducing the amount of human effort needed over time. This feedback cycle is what makes HITL scalable—it learns from itself.
Strategic Techniques to Supercharge HITL
Active Learning in the Real World
Active learning focuses on selecting the most informative data points for annotation, thereby optimizing resource utilization.
Sampling Strategies:
- Uncertainty Sampling: Targeting data where the model’s predictions are least confident.
- Diversity Sampling: Ensuring a broad representation of data scenarios.
Leveraging Weak Supervision and Programmatic Labeling
Weak supervision accelerates the annotation process by using rules and heuristics to generate initial labels, which are then refined by human annotators.
Tool Example: Snorkel
- Combine labeling functions
- Filter noisy labels
- Use confidence scores to triage for human review
This approach significantly cuts down on manual labor, particularly for tasks that follow predictable or repetitive patterns.
RLHF: Aligning Models with Human Values
In RLHF, human reviewers assess and rate model-generated outputs, helping steer the system toward more accurate and acceptable responses.
Implementation Considerations:
- Preference Ranking: Humans compare model outputs to determine the most appropriate responses.
- Feedback Integration: Incorporating human judgments into the model’s learning process.
Building a Robust Annotation Ecosystem
Choosing the Right Platform
Choosing the right annotation platform is crucial for efficiency and scalability.
Key Features to Consider:
- Multi-modal Support: Ability to handle various data types (text, images, audio, video).
- Collaboration Features: Enable smooth communication and task coordination between annotation team members.
- Quality Assurance Tools: Use integrated checks and validation systems to maintain high labeling accuracy and consistency.
- API Integration: Seamless connection with existing systems and workflows.
Orchestration and Workflow Management
Efficient workflow management ensures timely and accurate annotations.
Best Practices:
- Task Routing: Assigning tasks based on annotator expertise and availability.
- Integration with MLOps: Aligning annotation workflows with machine learning operations for seamless model updates.
Building and Managing Annotation Teams
A well-trained annotation team is essential to uphold the integrity and reliability of your labeled datasets.
Considerations:
- In-house vs. Outsourced: Evaluating the trade-offs between internal teams and external vendors.
- Training and Calibration: Providing comprehensive training and regular assessments to ensure consistency.
- Ethical Guidelines: Promote fair pay, safe environments, and transparent for all annotation contributors.
Data Governance and Security
Protecting data integrity and privacy is paramount.
Strategies:
- Privacy Safeguards: Strip or mask any personal identifiers in datasets to protect user confidentiality and comply with privacy standards.
- Compliance: Adhering to regulations like GDPR and HIPAA.
- Secure Infrastructure: Implementing robust security measures to prevent data breaches
V2Solutions: Enabling Scalable, High-Quality Human-in-the-Loop for Real-World AI
V2Solutions brings operational scale and precision to annotation and human-in-the-loop (HITL) workflows across AI applications. Our experience spans structured and unstructured data, multimodal labeling, and reinforcement learning from human feedback (RLHF). With deep delivery expertise and flexible infrastructure, we help ML teams integrate high-quality human input where it’s most impactful—without adding overhead or compromising quality.
Our process is grounded in transparent QA, domain-specific onboarding, and workflow customization. From pre-labeling to final audit, we work inside client ecosystems or offer platform support, always focusing on reliable throughput and evolving needs.
We don’t promise magic. We deliver predictable human input at scale, refined through collaboration, feedback loops, and measurable KPIs.
Scaling High-Precision Annotations for Autonomous Driving
Client: Leading AI firm in autonomous vehicle technology
The Challenge
- Required accurate labeling of complex, overlapping street imagery
- Needed to identify lanes, signs, and pedestrians under varied conditions
- Urgent need to scale without compromising quality
The Solution
- Deployed custom annotation workflows with semantic segmentation
- Used AI-assisted pre-labels refined by expert annotators
- Applied a three-tier QA process using IoU metrics
The Results
- Saved 1,000+ person-hours
- Increased accuracy from 85% to 97%
- Achieved 95% precision, 94% recall
Your Data Labeling Strategy Is Your AI Strategy
Annotation is no longer a backend chore. It’s a strategic function—the fuel, compass, and foundation of your AI.
Human-in-the-loop pipelines make this scalable, reliable, and adaptive. But only if you build them right:
- With clear strategy.
- With smart data prioritization.
- With operational rigor.
- And with human reviewers that understand both your domain and your model goals.
V2Solutions is here to help you do just that.
Ready to scale your AI model with smarter annotation workflows?
At V2Solutions, we don’t just label data—we build scalable, high-impact HITL pipelines that drive model precision and reduce costs. Whether you need active learning, RLHF, or multi-modal annotation at scale, our team is ready to embed with yours.
Schedule a free consultation now. Let’s design a data pipeline that powers real results.
Author