Table of Contents
Seamless and Real-Time Ingestion for Multi-sourced data Using an Exclusive AWS Architectural Solution

Introduction
Data storage is the “Soul” of any cloud platform; a platform’s performance is reflected in how effectively data is organized and leveraged. With consistently growing data volume, the cloud architecture must adapt to volatile requirements.
The whitepaper elaborates on a solution based on AWS cloud architecture that enables real-time data ingestion from external or cloud platforms and real-time data storage on a data lake. This functionality is specifically tailored for situations where there is a need for storing and organizing large amounts of real-time data on a data lake and direct access from the Lake without being loaded.
The data engineering part of the solution has been designed with 3 different ways of data ingestion scenarios:
- Data ingestion from Redshift
- Data ingestion from S3, and
- Data ingestion from streaming sources
Components and their Features
The key components of the solution are illustrated below:
Amazon S3
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can use Amazon S3 to store and protect any amount of data for various use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides management features to optimize, organize, and configure access to your data to meet your specific business, organizational, and compliance requirements.
Lambda
Lambda is a compute service that lets you run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure and performs all the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, and logging. With Lambda, you can run code for virtually any application or backend service.
Amazon Kinesis Data Stream
It collects and processes large streams of data records in real-time. You can create data-processing applications, known as Kinesis Data Streams applications, which reads data from a data stream as data records.
The producers continually push data to Kinesis Data Streams, and the consumers process the data in real-time. Consumers can store their results using an AWS service such as Amazon DynamoDB, Amazon Redshift, or Amazon S3.
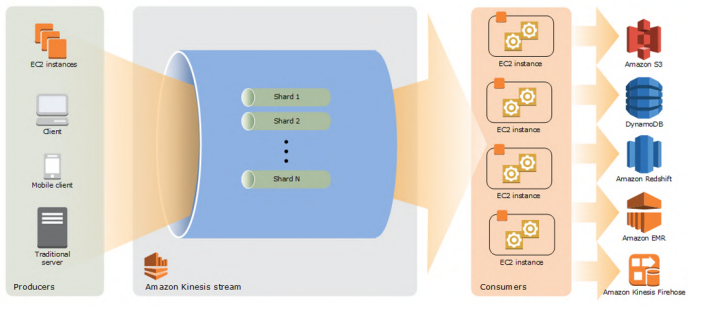
Amazon Kinesis Data Firehose
Firehose is the easiest way to load streaming data into data stores and analytics tools. Kinesis Data Firehose is a fully managed service that makes it easy to capture, transform, and load massive volumes of streaming data from hundreds of thousands of sources into Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Kinesis Data Analytics, generic HTTP endpoints, and service providers like Datadog, New Relic, MongoDB, and Splunk, enabling near real-time analytics and insights.
AWS Glue
AWS Glue is a serverless data integration service that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources. You can use it for analytics, machine learning, and application development. You can visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your data lakes. Also, you can immediately search and query cataloged data using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
- Data Catalog and crawlers: The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. You must catalog this data to create your data warehouse or data lake. The AWS Glue Data Catalog is an index of your data’s location, schema, and runtime metrics. You use the information in the Data Catalog to create and monitor your ETL jobs. Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store. Typically, you run a crawler to take inventory of the data in your data stores, but there are other ways to add metadata tables to your Data Catalog.
Amazon Athena
Amazon Athena is an interactive query service that easily analyzes data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Athena is easy to use. You must point your data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare your data for analysis. It makes it easy for anyone with SQL skills to quickly analyze large-scale datasets. Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to:
- create a unified metadata repository across various services,
- crawl data sources to discover schemas
- populate your Catalog with new and modified table and partition definitions, and
- maintain schema versioning
Amazon QuickSight
Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to your co-workers. Amazon QuickSight connects to your data in the cloud and combines data from many different sources. QuickSight can include AWS data, third-party data, big data, spreadsheet data, SaaS data, B2B data, and more in a single data dashboard. As a fully managed cloud-based service, Amazon QuickSight provides enterprise-grade security, global availability, and built-in redundancy.
MWAA
Amazon Managed Workflows for Apache Airflow (MWAA) is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud at scale. Apache Airflow is an open-source tool used to programmatically author, schedule, and monitor sequences of processes and tasks referred to as “workflows.” With Amazon MWAA, you can use Airflow and Python to create workflows without managing the underlying infrastructure for scalability, availability, and security. Amazon MWAA automatically scales its workflow execution capacity to meet your needs and is integrated with AWS security services to help provide you with fast and secure access to your data.
Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. It allows leveraging of data to gain insights for your business and customers.
The process starts with creating a data warehouse to launch a set of nodes called an Amazon Redshift cluster. After provisioning your cluster, you can upload your data set and perform data analysis queries. Regardless of the size of the data set, Amazon Redshift offers fast query performance using the same SQL-based tools and business intelligence applications.
Redshift Spectrum
Amazon Redshift Spectrum is a feature within Amazon Web Services’ Redshift data warehousing service that lets a data analyst conduct fast, complex analysis on objects stored on the AWS cloud. With Redshift Spectrum, an analyst can perform SQL queries on data stored in Amazon S3 buckets.
It saves time and money as it eliminates the need to move data from a storage service to a database and instead directly queries data inside an S3 bucket. Redshift Spectrum also expands the scope of a given query because it extends beyond a user’s existing Redshift data warehouse nodes and into large volumes of unstructured S3 data lakes.
SageMaker
Amazon SageMaker is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models and directly deploy them into a production-ready hosted environment.
Architecture in Detail
The architectural solution for the cloud platform leverages the features of the best-fitting components that provide seamless data flow and retrieval.
The image below represents the complete solution’s components, data flow, and processes.
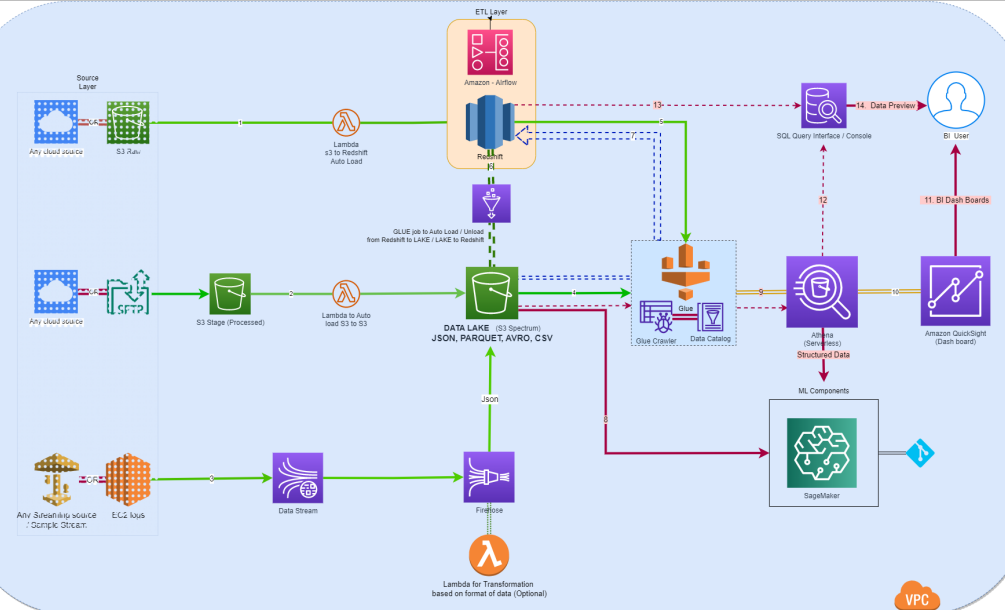
The image also explains the integration of the various components and the data flow. The solution module’s data is ingested from any cloud or external source.
The data flow is illustrated as follows:
- Data source for Redshift is a flat-file landing in S3. Once the file lands, Lambda will automatically perform a data transfer from the flat file to the Redshift table. The data has been taken as raw or unprocessed data.
- Data source for S3 is assumed as externally based or cloud-based, and the incoming data is treated as structured or unstructured. The data file will be automatically copied into Lake with the help of Lambda.
- The streaming data will be coming from an external source to the Kinesis data stream, which is then automatically consumed by Amazon Kinesis Data Firehose. Kinesis Data Firehose loads streaming data into data lakes, data stores, and analytics services. Data captured by this service can be transformed and stored into an S3 bucket as an intermediate process. The streaming data can be transformed into multiple formats using the Lambda function based on requirements.
- The lake data has been accessed by Glue crawlers that will run on top of the data lake, which will create metadata. The crawler has been configured as a file input event-based trigger, or it can be scheduled to a specific interval. Crawlers will crawl on top of different file formats of data (Avro, Parquet, JSON, CSV), and an external schema will be created on top of the Glue cataloged data schema.
- Another set of crawlers has been configured on Redshift, which will read the data warehouse and create metadata. Here the Redshift data will be accessed through the Glue catalog, and an external schema will be0020created with the respected Glue catalog.
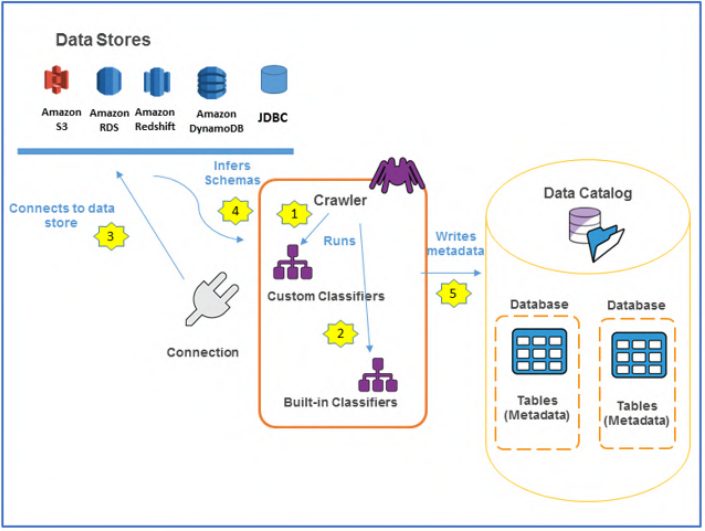
The following is the general workflow for how a crawler populates the AWS Glue Data Catalog:
- A crawler runs any custom classifiers you choose to infer the format and schema of your data. You provide the code for custom classifiers, which run in the order you specify.
- The first custom classifier to successfully recognize the structure of your data is used to create a schema. Custom classifiers lower in the list are skipped.
- If no custom classifier matches your data’s schema, built-in classifiers try to recognize your data’s schema. An example of a built-in classifier recognizes JSON.
- The crawler connects to the data store, and some stores require connection properties for crawler access.
- The inferred schema is created for your data.
- The crawler writes metadata to the Data Catalog. A table definition contains metadata about the data in your data store. The table is written to a database, i.e., a table container in the Data Catalog. A table’s attributes include classification, a label created by the classifier that inferred the table schema.
Here the green streams indicated the primary data channels between key components; there won’t be any redundant data in Lake or Redshift.
- A Glue ETL job is configured to load or unload the data between Lake and Redshift. It is dedicated to the data archiving (Redshift to Lake) process and can also be used on special scenarios like reducing frequent reads of small tables through the Redshift spectrum (7), which is costlier.
- This stream refers to the Redshift spectrum, which is a special feature in Redshift that allows us to read the data directly from any file source through Redshift, here the spectrum schema has been created on top of Lake, and the data can be queried through Redshift query interface, this data can be consumed for data transformation process on top of Redshift.
- This channel refers to data input to SageMaker, a fully managed machine learning service. This stream indicated the unstructured data (images etc.) feed from Lake to SageMaker. The SageMaker consumes analytics data directly from Athena.
- Catalogued data schema can be directly accessible from Athena (a query engine). Athena will be the single and crucial point where the entire data can be accessed without being moved or copied. Users can access Redshift data, Lake data, or data from streaming sources directly, and it will be the feed for any analytics.
- Processed data feed will flow to QuickSight, a BI tool for data analytics in AWS. QuickSight can directly access Athena, Redshift, and direct streaming source data. The data from different sources will combine to create dashboards for real-time analytics.
- BI/DB users can directly query the data from the Athena console or through any SQL interface which supports the Athena connection. The user can access dashboards from the QuickSight console.
- The user can query directly on top of the Redshift cluster based on required situations.
ETL layer has been configured with Airflow (MWAA) as an ETL tool orchestrated on the Redshift cluster for data transformation use cases.
Highlights
The AWS architectural solution holds some striking highlights that make it stand out. They are:
- End-to-end cloud-based Data engineering solution
- Fully Automated data flows
- Event-driven triggering mechanism
- No Data Redundancy
- Fully integrated system with multiple access points of the single data source.
- Muti format data handling (JSON, CSV, parquet, Avro, etc.)
- Multiple feeds with different mechanisms (Redshift, S3, Streaming data, SFTP, etc.)
- One centralized Catalog to access anything from any source.
References
1. https://docs.aws.amazon.com/