Executive Summary
Data has always been central to cloud architecture, but at scale, the challenge is no longer just about storing or processing it. In a data-local AI architecture, the real constraint is how data moves.As enterprises expand their AI capabilities, they are dealing with increasingly distributed data sources—spanning cloud platforms, streaming systems, and external environments. Traditional architectures attempt to bring this data together into centralized lakes or warehouses before it can be processed. While this model simplifies access, it introduces a growing set of inefficiencies that become more pronounced as systems scale.Every movement of data—across regions, services, or pipelines—adds latency. Every transfer contributes to rising cloud costs. And every centralized dependency creates contention when multiple workloads attempt to access the same data simultaneously.This is where data-local AI architecture is emerging as a critical design approach. Instead of moving data across systems for processing, it enables compute to operate closer to where data resides, reducing transfer overhead while improving performance and scalability.What is becoming clear across modern AI systems is that performance limitations are no longer driven primarily by compute capacity, but by how frequently and how far data must travel before it can be used..This whitepaper explores an AWS-based architectural approach that addresses these challenges by minimizing unnecessary data movement. Rather than optimizing pipelines for faster transfer, the design focuses on enabling data-local access, where compute operates closer to the data itself. The result is a system that supports real-time ingestion from multiple sources while maintaining efficiency, scalability, and responsiveness.
The Growing Impact of Data Gravity on Data-Local AI Architecture
As data accumulates within a system, it begins to exert what is often referred to as “data gravity.” Larger datasets become increasingly difficult and expensive to move, and applications naturally shift closer to where the data resides. In distributed AI environments, this effect is amplified.
In early-stage architectures, moving data into a central system may appear manageable. However, as organizations scale across geographies and workloads, the cost of this approach compounds. Data pipelines multiply, inter-region transfers increase, and latency becomes less predictable.
Three systemic challenges tend to emerge:
- Latency accumulation across workflows: Data must pass through ingestion, transformation, and storage layers before it becomes available for inference or analytics. Each step introduces a delay, which becomes critical in real-time use cases.
- Rising transfer and egress costs: Cloud environments charge for data movement, especially across regions. As AI workloads grow, these costs are often scaled faster than computing expenses.
- Centralized bottlenecks under load: When multiple AI models, dashboards, and services rely on the same centralized data source, contention increases. This results in degraded performance and inconsistent throughput.
These challenges cannot be resolved simply by adding more compute resources or optimizing individual pipelines. They require a shift in how systems are designed.
Rethinking Architecture: From Movement to Data-Local AI Architecture
Traditional data architectures are built around a simple premise: consolidate data, then process it. While this approach provides a single source of truth, it assumes that moving data is relatively inexpensive and does not significantly impact performance.
At scale, that assumption no longer holds.
A data-local architecture reverses this premise. Instead of prioritizing consolidation, it prioritizes proximity. Data is stored in distributed layers, and compute is positioned close to those layers. Query engines operate directly on the data where it resides, and transformation logic is applied at or near the point of ingestion.
This shift introduces several advantages. By reducing the need for movement, systems naturally experience lower latency and reduced transfer costs. At the same time, distributed access prevents the formation of centralized bottlenecks, allowing multiple workloads to operate independently.
Importantly, this is not about eliminating structure or governance. Rather, it is about decoupling access from movement—ensuring that data can be discovered, queried, and processed without requiring physical relocation.
Core AWS Services Enabling a Data-Local Model
The architecture presented in this whitepaper leverages AWS services not as isolated tools, but as components of a coordinated system designed to minimize data movement while maintaining real-time accessibility.
At the foundation is Amazon S3, which serves as the primary storage layer. Unlike traditional data lakes that require data to be processed before use, S3 in this architecture functions as a live data layer. Data stored here is immediately accessible to query engines and downstream services, eliminating the need for repeated transfers.
Processing at the point of ingestion is enabled by AWS Lambda. By triggering compute functions as data arrives, Lambda reduces reliance on downstream transformation pipelines. This allows data to be prepared for use without first being routed through multiple intermediate systems.
Streaming data is handled through Amazon Kinesis, which captures and delivers real-time data flows. With services such as Kinesis Data Firehose, data can be transformed and delivered into storage systems in near real time, ensuring that it is ready for analysis without additional movement.
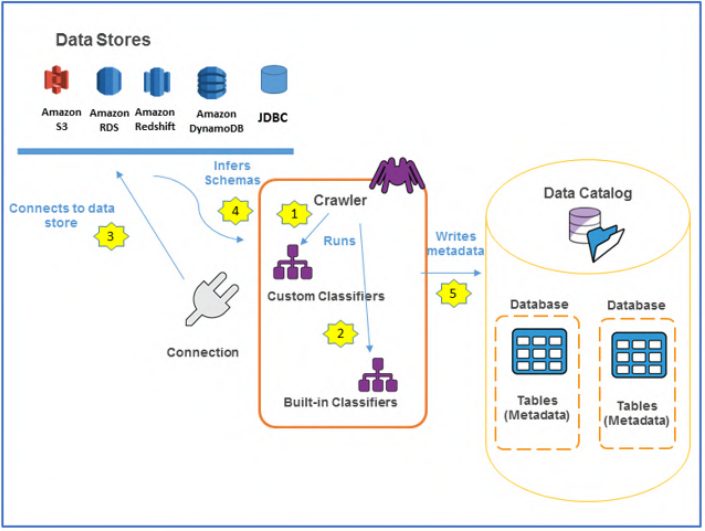
AWS Glue introduces a critical layer of abstraction through metadata. Instead of physically restructuring data, Glue crawlers scan datasets and generate schema definitions that are stored in the Data Catalog. This enables multiple services to interact with the same data in place, without creating duplicates.
Amazon Athena plays a central role in this architecture by providing a query layer that operates directly on data stored in S3. Users and systems can execute SQL queries across large datasets without requiring data to be loaded into a separate engine. This effectively transforms storage into an active analytics layer.
Amazon Redshift and Redshift Spectrum extend this capability by enabling hybrid querying across both warehouse and lake data. This allows organizations to maintain high-performance analytics for structured workloads while still leveraging distributed storage for large-scale datasets.
Machine learning workflows are supported by Amazon SageMaker, which consumes data directly from S3 and Athena. By avoiding additional data preparation steps, SageMaker reduces the time required to train and deploy models.
Visualization and reporting are handled by Amazon QuickSight, which connects directly to these data sources to generate real-time dashboards. Orchestration across the system is managed by Amazon MWAA, ensuring that workflows remain coordinated without introducing centralized dependencies.
Data-Local AI Architecture in Practice: Multi-Source Ingestion Without Centralization
The architecture is designed to support multiple ingestion scenarios while maintaining a consistent principle: data should remain accessible in place.
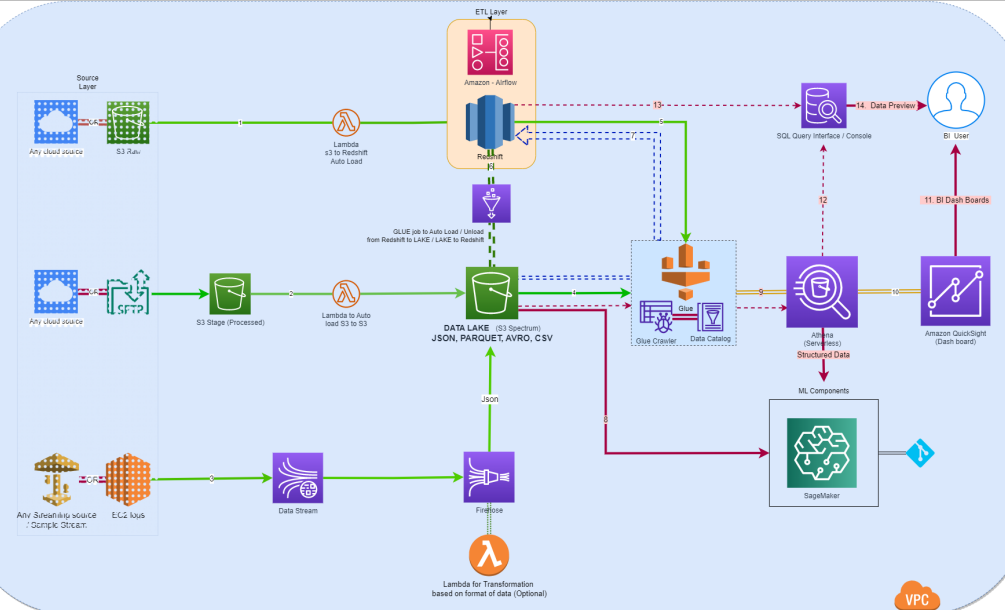
Data originating from external systems or cloud platforms is ingested directly into Amazon S3. Once stored, it becomes immediately available for querying through Amazon Athena. There is no requirement to move the data into a separate system before it can be used.
Streaming data follows a similar pattern. It flows through Amazon Kinesis, where it is processed and delivered into S3 in near real time. Transformation logic can be applied during this process using AWS Lambda, ensuring that the data is ready for consumption as soon as it arrives.
For scenarios requiring structured, high-performance analytics, data can be loaded into Amazon Redshift. However, this is done selectively. In many cases, queries can be executed directly on data stored in S3 through Redshift Spectrum, reducing the need for duplication.
AWS Glue continuously catalogs data across both storage and warehouse layers, ensuring that all datasets remain discoverable. At the center of the architecture, Amazon Athena provides a unified query interface, allowing users and systems to access data across sources without triggering movement.
This design ensures that ingestion, processing, and consumption are integrated, but not dependent on centralized data relocation.
Implications for AI Workloads
The benefits of a data-local architecture become particularly evident in AI systems, where performance and responsiveness are closely tied to data access patterns.
In traditional architectures, inference workflows often depend on data that must be retrieved from centralized storage. This introduces delays that can impact real-time decision-making. As workloads scale, these delays become more pronounced, leading to inconsistent performance.
By contrast, a data-local approach reduces the distance between data and compute. Models can access the data they need directly, without waiting for it to be transferred across systems. This leads to faster inference, more predictable performance, and improved user experience.
Cost efficiency is also significantly improved. By minimizing data transfer, organizations reduce their reliance on inter-region and service-level movement, which are often major contributors to cloud spend.
At the same time, distributed access allows multiple AI workloads to operate concurrently without competing for centralized resources. This improves scalability and ensures that systems can handle increasing demand without degradation.
Design Considerations for Data-Local AI Architecture in Enterprise Adoption
While the benefits of data locality are clear, implementing this approach requires thoughtful design decisions.
Data placement becomes a critical factor. Instead of storing all data in a single location, organizations must consider where data will be used most frequently and align storage accordingly. This ensures that compute can be positioned close to the data it depends on.
Governance and compliance also play an important role. In regulated industries, data residency requirements may dictate where data can be stored and processed. A data-local architecture must account for these constraints while still enabling efficient access.
Cost management practices must evolve as well. Traditional FinOps models focus heavily on compute usage, but in data-local systems, data movement becomes an equally important factor. Monitoring transfer costs and understanding data access patterns are essential for maintaining efficiency.
Finally, orchestration must be designed to support distributed systems. Tools such as Amazon MWAA enable coordination across services without forcing centralization, ensuring that workflows remain scalable and resilient.
Conclusion
As AI systems continue to scale, the limitations of movement-heavy architectures are becoming increasingly apparent. Data transfer is no longer just an operational concern—it is a fundamental architectural constraint that impacts performance, cost, and scalability.
The AWS-based architecture outlined in this whitepaper addresses this challenge by shifting the focus from movement to locality. By enabling real-time ingestion, in-place querying, and distributed processing, it creates a system that is better aligned with the demands of modern AI workloads.
The shift is both practical and strategic. Organizations that adopt data-local architectures are not simply optimizing their existing systems; they are redefining how those systems operate at scale.
The direction forward is clear: the most efficient AI systems will not be those that move data faster, but those that are designed to move it less.